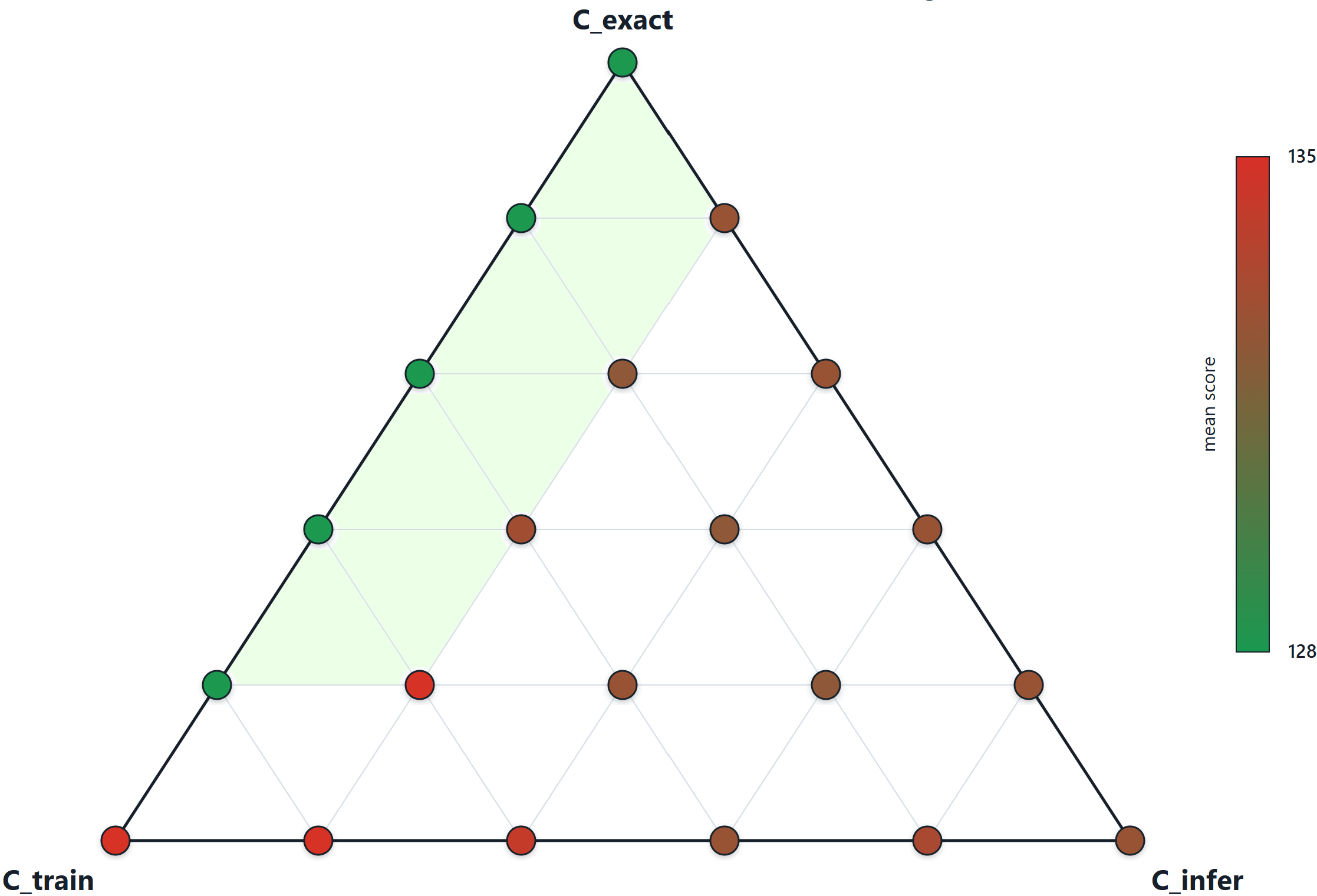
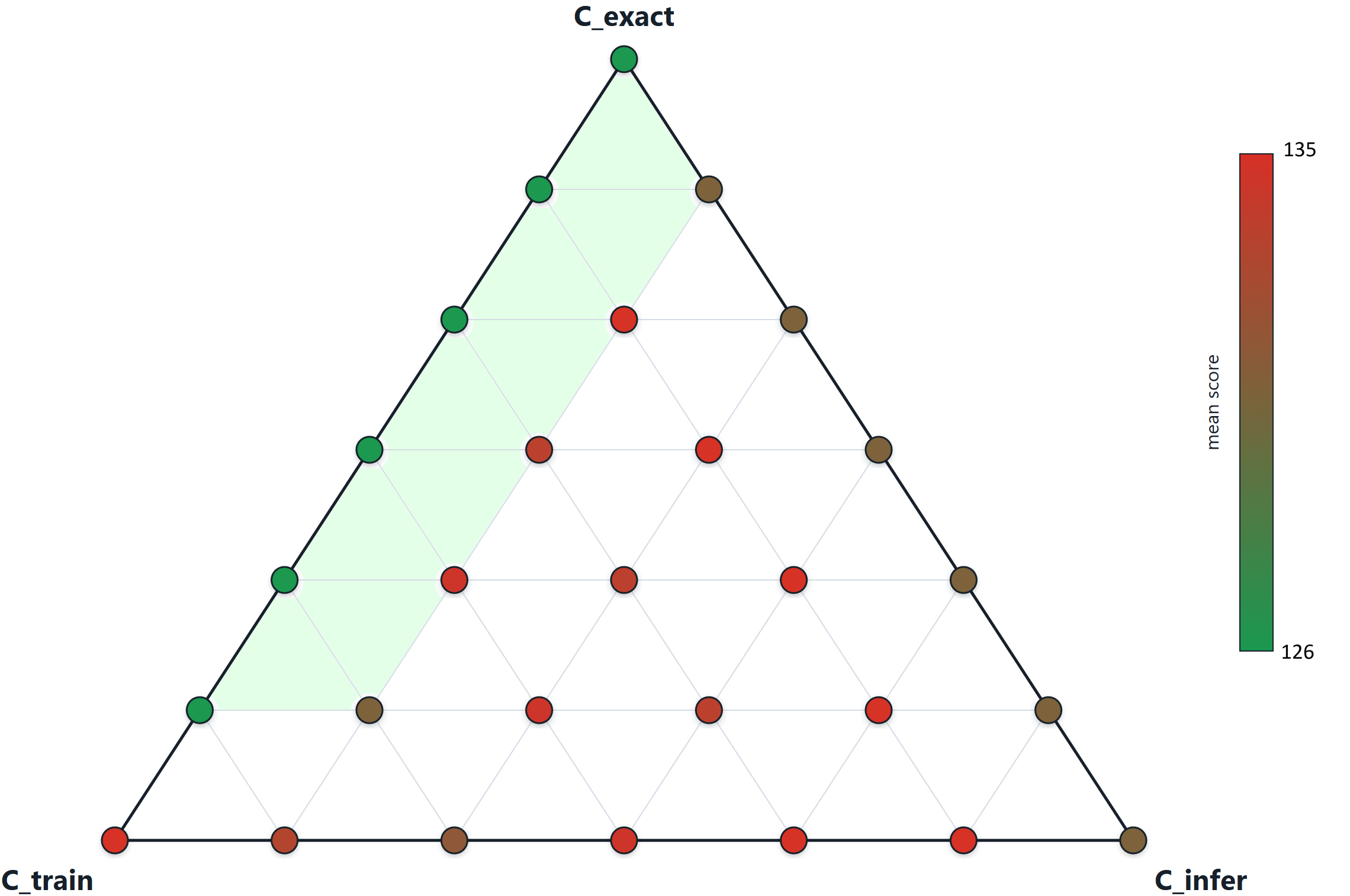
How should a fixed compute budget be allocated across these components? I propose a very strong conjecture.
Master Conjecture: For every fixed problem class \(\mathcal{P}\), the optimal allocation of the total compute budget \(C\) is a fixed-ratio allocation
\(C_{train}^{*}, C_{infer}^{*}, C_{exact}^{*} = \alpha_{\mathcal{P}}C, \beta_{\mathcal{P}}C, \gamma_{\mathcal{P}}C\)
where \(\alpha_{\mathcal{P}} + \beta_{\mathcal{P}} + \gamma_{\mathcal{P}} = 1\) are constants that depend only on the problem class \(\mathcal{P}\).
In my PhD Thesis "Machine Learning-based Search in Combinatorial Optimization" I prove the Master Conjecture for some tree-search models. These models are highly simplified, and it might be true that the optimal allocation has a different behavior depending on the problem class \(\mathcal{P}\). In some cases it may be true that \(C_{exact}^{*}\) scales as \(O(C)\) but in others only as \(O(C / \log C)\) or even \(O(\log C)\). Nevertheless, it is interesting that empirical experiments in combinatorial games like Hex and Chess show the same form of scaling laws.
Example 1: Chess AI Engine
Public numerical data on Chess Engines like Stockfish reports an \(\approx 26\) ELO gain from doubling of train compute (as described in SFNNv6), \(\approx 110\) ELO gain from doubling of inference-time compute (obtained from data on 20% time odds ELO change), and \(\approx 3\) ELO gain from doubling of exact compute (Syzygy tablebases). It follows that the optimal ratios can be computed by maximizing the ELO:
\(\mathrm{Maximize\;\;} E(C) \approx 26 \log_2 C_{train} + 110 \log_2 C_{infer} + 3 \log_2 C_{exact}\)
\(\mathrm{s.t.\;\;\;} C_{train} + C_{infer} + C_{exact} = C\)
Solving this optimization problem gives:
\(C_{train} : C_{infer} : C_{exact} \approx 18\% : 80\% : 2\%\)
Note that training happens once, while test-time inference and exact algorithms are used every game. In practice, people don't allocate 4 times more compute on inference for a single game than on training. If you know the number of games \(N\) in advance, it is easy to find that the optimal allocation budget changes to \((18N : 80 : 2)\). Note that in scientific discovery applications, inference may happen only a couple of times.
Example 2: AI for Science, AlphaTensor, AlphaEvolve
DeepMind has built many AI systems for search and discovery: AlphaZero, AlphaFold, AlphaTensor6, AlphaEvolve7, AlphaProof8. Some of these results were later improved9 by adding classical CS algorithms and search techniques. Here I provide a table that shows compute allocation in these systems, highlights potential design improvements, and shows how \(C_{exact}\) clarifies complex design decisions.
| System | Allocation Structure | Possible Improvements |
|---|---|---|
| AlphaTensor | Large \(C_{train}\) and \(C_{infer}\) for neural network training and tree search. \(C_{exact}\) is near zero, only used for data augmentation and permutations. | A natural extension would be to combine tensors and expressions proposed by a neural network with exact classical algorithms such as MILP solvers and flip graph search. |
| AlphaEvolve | Large \(C_{train}\) for LLM pre-training, post-training, RL. Large \(C_{infer}\) for reasoning model inference. Task-dependent \(C_{exact}\) budget. | Initially FunSearch was used to sample programs that generate solutions. With this design, \(C_{exact}\) would only be used for program evaluation. Instead, in AlphaEvolve DeepMind introduced a new kind of \(C_{exact}\) scaling: they sample search algorithms, which are then executed with a significant compute budget. |
| AlphaProof | Large \(C_{train}\) for training. Large \(C_{infer}\) for reasoning models and tree search. Task-dependent \(C_{exact}\) for compilation with Lean kernel, tactics execution. | Recent Lean Coding agents by Harmonic and AxiomMath likely include significantly more \(C_{exact}\) budget for: fixing Lean compilation errors, decomposing into Lemmas, and stronger compilation engines. |